
DEEPMIND HA SCOPERTO NUOVI DETTAGLI SU COME LA DOPAMINA AIUTA IL CERVELLO AD APPRENDERE
Un algoritmo che apprende attraverso le ricompense può dimostrare come il nostro cervello faccia lo stesso
OTTIMIZZANDO GLI ALGORITMI DI APPRENDIMENTO PER RINFORZO, DEEPMIND HA SCOPERTO NUOVI DETTAGLI SU COME LA DOPAMINA AIUTA IL CERVELLO AD APPRENDERE
di Karen Hao
15.01.2020
Nel 1951, Marvin Minsky, allora studente ad Harvard, utilizzò osservazioni dal comportamento animale per cercare di progettare una macchina intelligente. Prendendo spunto dalle idee presenti nell’opera del fisiologo Ivan Pavlov, che notoriamente usava i cani per mostrare come gli animali imparano attraverso punizioni e ricompense, Minsky creò un computer che poteva continuamente imparare attraverso rinforzi simili per risolvere un labirinto virtuale.
All’epoca, i neuroscienziati dovevano ancora capire i meccanismi interni al cervello che permettono agli animali di apprendere in questo modo. Ma Minsky fu comunque in grado di imitare vagamente quel comportamento, facendo quindi avanzare l’intelligenza artificiale. Diversi decenni dopo, mentre l’apprendimento per rinforzo continuava a maturare, a sua volta aiutava il campo della neuroscienza a scoprire quei meccanismi, alimentando un circolo virtuoso di avanzamento tra i due campi.
In un articolo pubblicato oggi su Nature, DeepMind, sussidiaria di Alphabet’s AI, ha usato ancora una volta le lezioni di apprendimento per rinforzo per proporre una nuova teoria sui meccanismi di ricompensa all’interno del nostro cervello. L’ipotesi, supportata dai primi risultati sperimentali, potrebbe non solo migliorare la nostra comprensione della salute mentale e della motivazione. Potrebbe anche convalidare l’attuale direzione della ricerca sull’intelligenza artificiale verso la costruzione di un’intelligenza generale più umana.
A un livello elevato, l’apprendimento per rinforzo segue le intuizioni scaturite dai cani di Pavlov: è possibile insegnare a un agente a padroneggiare compiti complessi solo atraverso feedback positivi e negativi. Un algoritmo inizia ad apprendere un’attività assegnata prevedendo in modo casuale quale azione potrebbe fargli ottenere una ricompensa. Quindi esegue l’azione, osserva la ricompensa reale, e regola la sua previsione in base al margine di errore. Su milioni o addirittura miliardi di prove, gli errori di previsione dell’algoritmo convergono a zero, a quel punto sa esattamente quali azioni intraprendere per massimizzare la sua ricompensa e completare così il suo compito.
Si scopre che il sistema di ricompense del cervello funziona più o meno allo stesso modo-una scoperta fatta negli anni ’90, ispirata dagli algoritmi di apprendimento per rinforzo. Quando un essere umano o animale sta per compiere un’azione, i suoi neuroni dopaminergici fanno una previsione sulla ricompensa attesa. Una volta ricevuta una ricompensa effettiva, rilasciano una quantità di dopamina che corrisponde all’errore di predizione. Una ricompensa migliore del previsto innesca un forte rilascio di dopamina, mentre una ricompensa peggiore del previsto sopprime la produzione del prodotto chimico. La dopamina, in altre parole, funge da segnale di correzione, dicendo ai neuroni di regolare le loro previsioni fino a quando non convergono alla realtà. Il fenomeno, noto come errore di previsione della ricompensa, funziona in modo molto simile a un algoritmo di apprendimento per rinforzo.
Il nuovo documento di DeepMind si basa sulla stretta connessione tra questi meccanismi di apprendimento naturali. Nel 2017, i suoi ricercatori hanno introdotto un algoritmo di apprendimento per rinforzo migliorato che da allora ha sbloccato prestazioni sempre più impressionanti su vari compiti. Ora ritengono che questo nuovo metodo possa offrire una spiegazione ancora più precisa di come funzionino i neuroni della dopamina nel cervello.
In particolare, l’algoritmo migliorato cambia il modo in cui prevede i premi. Considerando che il vecchio approccio ha stimato le ricompense come un singolo numero-inteso a eguagliare il risultato medio previsto- il nuovo metodo li rappresenta in modo più accurato come una distribuzione. (Pensate per un attimo ad una slot machine: potete vincere o perdere seguendo una certa distribuzione. Ma in nessun caso ricevereste il risultato medio previsto).
La modifica si presta ad una nuova ipotesi: i neuroni della dopamina prevedono anch’essi i premi nella stessa modalità distributiva?
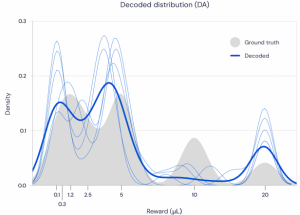
Misurando il comportamento dei neuroni della dopamina dei topi, i ricercatori hanno scoperto che la distribuzione delle predizioni dei neuroni (decodificata) ha seguito da vicino la distribuzione delle ricompense effettive (verità di base). DEEPMIND
“Questa è una bella estensione della nozione di codifica da parte della dopamina dell’errore di previsione della ricompensa”, scrive Wolfram Schultz in un’email, un pioniere nel comportamento dei neuroni della dopamina che non è stato coinvolto nello studio. “E’ sorprendente come questa semplicissima risposta della dopamina segua prevedibilmente schemi intuitivi dei processi di apprendimento biologici di base che stanno ora divenendo una componente dell’AI”.
Lo studio ha implicazioni sia per l’intelligenza artificiale che per le neuroscienze. Innanzitutto, convalida l’apprendimento per rinforzo distributivo come percorso promettente verso capacità di intelligenza artificiale più avanzate. “Se il cervello lo usa, è probabilmente una buona idea”, dichiara Matt Botvinik, direttore della ricerca sulle neuroscienze di DeepMind e uno dei principali autori del documento, durante un incontro con la stampa. “Ci dice che queasta è una tecnica computazionale che può scalare in situazioni del mondo reale. Si adatterà bene con altri processi computazionali”.
In secondo luogo, potrebbe offrire un aggiornamento un aggiornamento importante a una delle teorie canoniche della neuroscienza sui sistemi di ricompensa del cervello, che a sua volta potrebbe migliorare la nostra comprensione di tutto, dalla motivazione alla salute mentale. Cosa potrebbe significare, ad esempio, avere neuroni dopaminici “pessimisti” e “ottimisti”? Se il cervello ascoltasse selettivamente solo l’uno o l’altro, potrebbe portare a squilibri chimici e indurre depressione?
Fondamentalmente, grazie ad una ulteriore decodificazione dei processi mentali, i risultati fanno luce anche su ciò che crea la mente umana. “Ci dà una nuova prospettiva su ciò che accade nel nostro cervello durante la vita di tutti i giorni”, dice Botvinick.
TRATTO DA:
TRADUZIONE A CURA DI RENATO NETTUNO


